
01: Introduction

3DListening (3DL) immerses you virtually in space through a tailored, in-person group session in our 3DL Studio or as a remote, interactive presentation on a platform like Zoom.
As a versatile technique for understanding variations in sound, 3DL offers advantages across diverse scenarios—from envisioning unbuilt designs to solving acoustical issues in existing spaces, and even exploring virtual tours related to ongoing projects. It’s a key technology at Acentech that helps our clients unlock a richer auditory understanding of any environment.
02: 3DL Origins


ORIGINS
3DL began at Acentech in 2003, in the early stages of the design of the Art of the Americas wing at the Museum of Fine Arts Boston. Bringing together the Museum stakeholders, and the designers, Foster + Partners and cbt, in our 3DL Studio in Cambridge, we helped to achieve a design for the glass-enclosed Shapiro Family Courtyard that is both acoustically pleasant and inviting for visitors.
Since then, Acentech has developed techniques and processes to make the experience for 3DL participants more engaging and accessible, while extending the concept to cover a wide range of spaces and programs.
We continue to develop and improve our process to provide ever-more immersive and effective experiences with greater efficiency. The process described in this feature may be outdated by the time you read it! Contact us to experience the state of the art.
3DListening: Hear it for yourself

About this demonstration
03: The 3DL Experience
3DListening typically involves convening the project team in our 3DL Studio in Cambridge or Philadelphia, where loudspeakers are installed in a custom, high-resolution surround arrangement. This setup ensures a synchronized experience for all participants, fostering group discussion and decision-making.
Often, like in the sunlit top-level lounge of the Knight Executive Education Center project above, participants engage in group discussions while immersed in the modeled environment, gauging the ease or difficulty of communication in an active social space. This format provides realistic playback levels, allowing for a genuine perception of modeled sounds, such as the palpable sensation of a passing train or the distant chatter of a group.

In cases where physical gathering is impractical, we can present 3DListening experiences through online conferencing platforms like Zoom. Participants receive identical model conferencing headsets, accompanied by frequency correction filters. While this online format is convenient and effective for various listening scenarios, accurately judging loudness on headphones does pose challenges. To address this, we incorporate comparison listening features—such as close conversations in the modeled space—to provide reference points for assessing environmental loudness.

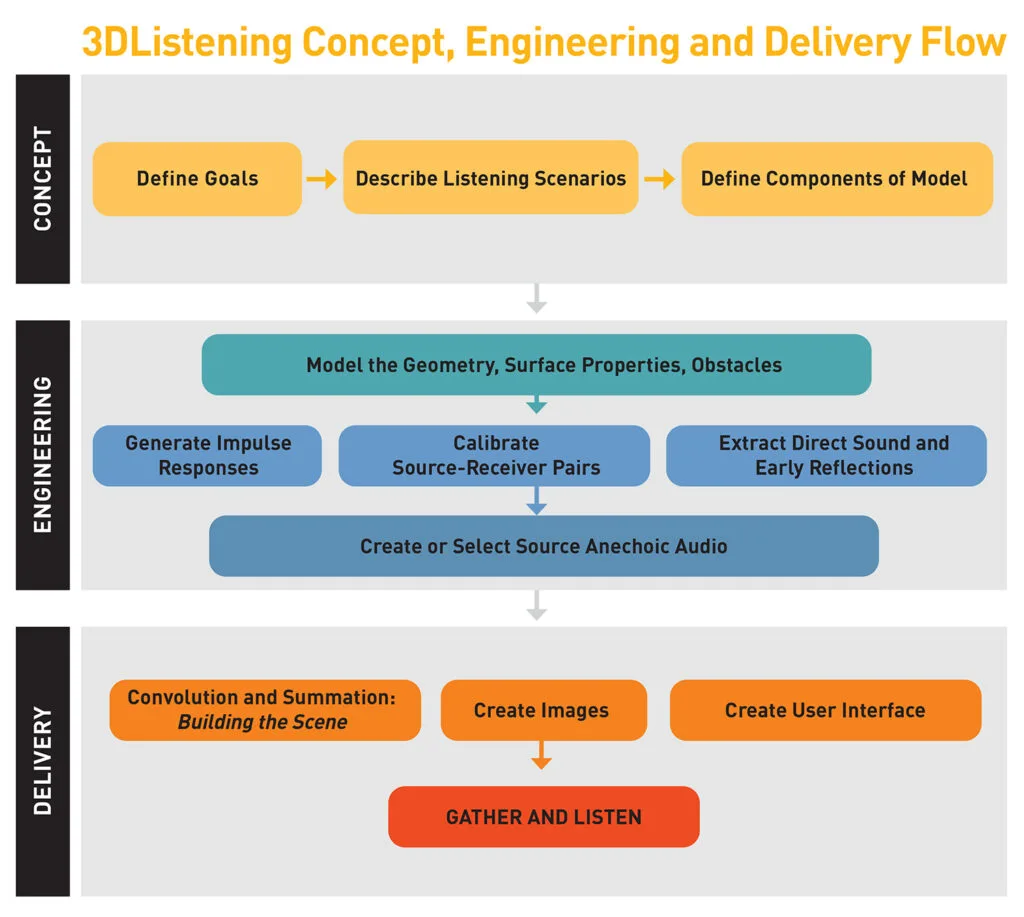
04: Creating 3DL: How it Works
3DL involves collaborating with clients and project teams to understand project goals and establish the needs of our listening exercise. Once these are in place, we create a computer model of the spaces, assign acoustical properties to the surfaces, place sound sources and listening positions, and generate impulse responses (explore the content below for more information). Then we combine these elements with anechoic recordings of the types of activities that will occur in the space, such as talking or music, before assembling these components into an interactive presentation.
The 3DL process in more detail:
What are we trying to determine or demonstrate, and what components of acoustical modeling are required? We assess components of acoustical modeling such as speech intelligibility, musical performance sound quality, reverberant buildup of activity sounds, and potential sleep disturbance from adjacent spaces or outdoor noise sources.
We detail the scenarios to be modeled based on anticipated space uses. For a musical performance, for example, we specify instruments, music style, and audience setup. In the case of a wedding reception, we define guest count, celebration mood, service areas, and music style. We envision realistic scenes aligned with 3DListening goals, capturing the space’s essence in human terms and contextualizing acoustical challenges.
This involves various elements: sound sources (e.g., people, instruments, loudspeakers, machinery, outdoor noise), listening locations (e.g., audience seats, adjacent rooms, different spots in a large space), space geometry and surface characteristics (reflective, absorptive, or scattering surfaces), and obstacles (windows, doors, walls). Here we consider the exercise’s goals in designing the model and presentation. For instance, assessing a lecturer’s intelligibility may require accounting for building mechanical noise. If evaluating speech communication in a conference room, outdoor vehicle noises could be a crucial factor. At this point, we sketch the user interface and storyboard the images and controls for participant interaction.
Enclosed spaces are typically modeled in 3D architectural software like Sketchup or Rhino, and then transferred to room acoustics modeling software such as CATT-Acoustic, Treble, or Pachyderm. In these programs, acoustic properties of surfaces, absorption coefficients, scattering, and the placement of sound sources and receivers are defined.
The room acoustics modeling software, usually CATT-Acoustic or Treble in our practice, generates impulse responses for each source-receiver pair in the modeled space. These responses include the direct sound, early reflections from nearby room surfaces, factors like time of arrival, strength, frequency spectrum, and direction of arrival. The impulse response serves as a unique “acoustical fingerprint” specific to a source-receiver pair in the space. It is a multi-channel digital audio file, commonly 4 channels, with 9 or 14 or more channels used for projects needing fine spatial resolution (see Ambisonics).
For projects requiring precise auditory localization or the evaluation of specific reflecting surfaces, distinguishing direct sound and early reflections from the overall impulse response is essential. We achieve this by employing a specialized Matlab signal processing routine to detect and extract these elements, resulting in individual impulse responses. This approach enables listeners to perceive nuances such as separation and blend among members of a string quartet.
3DListening often involves the evaluation of balance among different sound sources, like hearing a lecturer clearly among other ambient sounds. This involves precise adjustment of sound levels, accomplished in two layers. First, impulse responses are calibrated using information from the room acoustics modeling software, considering factors like source distance, directivity, and orientation. This calibration is usually executed through a Matlab script. The second layer involves level calibration during the selection and preparation of source audio material, as detailed below.
Each source in the acoustical model corresponds to a person, object, or group producing sound in the modeled space. To represent each source, we chose an audio recording captured in an anechoic environment (an environment without reflections or echoes). Anechoic recordings, obtainable from sound libraries, are often sourced from studios or specially treated spaces, and they lack reflected sounds.
Each project is different, and we often make new recordings of sounds specific to the use of a modeled space, utilizing our acoustically designed 3DL Studio, external facilities, or outdoor settings. For example, for the Virtual Paul’s Cross project, an actor-scholar authentically recited a John Donne sermon in an anechoic recording studio for use in our model and 3DL presentation of Donne’s speech in London’s Saint Paul’s Cathedral courtyard, viewable online. In another project, a string quartet was recorded individually in an anechoic chamber, providing isolated instrument recordings for realistic 3DL placement. This session also captured instrument directionality by placing microphones around each instrument, creating a composite source with distinct sounds projecting in various directions.

Sounds, whether recorded or chosen from a library, need assembly before integration into the model.
In acoustical modeling, a source location often involves various simultaneous sounds, like people dining and conversing. While it’s possible to model each element separately, it’s common to simplify them into a single compound source. Relevant sounds are combined into one audio file by merging recordings like conversations, dishware, and other ambient activities. These are mixed with level adjustments to achieve a realistic balance of voices and sounds.
After selection and assembly, the sound levels are calibrated relative to each other. This calibration considers varying levels among different sources or groups, unrelated to the acoustical effects of the modeled space. For example, a group conversation is louder than an individual speaker, and a passing train is louder than a car. These levels are set based on measured sound levels for each source type, obtained from our database or other reference sources. The assembly and level setting are done using audio editing software like Audacity, Reaper, and others.
Once we’ve modeled a space, defined surface acoustical properties, located sound sources and listening spots, computed calibrated impulse responses, and organized anechoic source audio file, we move on to the all important last step of 3DL: assembling the final scene.
05: Assembling the Scene
Developing the presentation in Max/MSP involves coding key signal processing functions and user controls, enabling participants to navigate the 3DL presentation. Users can manipulate buttons and switches to alter listening locations, manage sound sources, and choose architectural design options.
This process involves combining anechoic source audio files with source-receiver impulse responses to spatially position the sources in the room. It includes multiplying each digital sample of each channel of the impulse response audio file with the entire anechoic audio file and reassembling it into a new audio file, incorporating reverberation and other room effects from the impulse response. Real-time convolution within Max is facilitated by a specialized toolbox developed by researchers at the University of Huddersfield, UK.
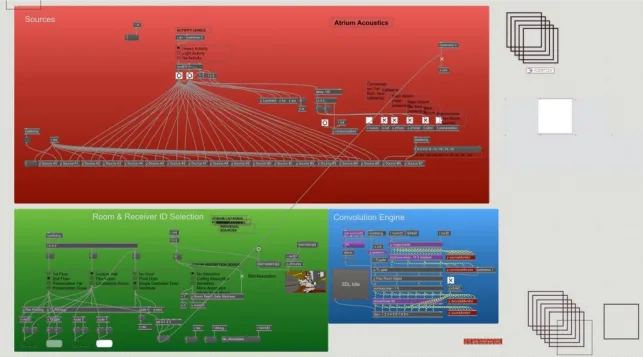
At each listening location, multiple sources in the space are heard. Each of these has its own source-receiver impulse response, and these must be summed with appropriate levels so they are heard together correctly by the listener.
At this point, the audio is in a multi-channel form known as B-format, which includes all directional information from the model and computations. This must be decoded, or rendered, to the loudspeaker configuration.
If the direct sound and early reflections have been extracted, these are assigned to the appropriate loudspeakers using vector-based amplitude panning (VBAP), which is a generalized multi-channel version of the traditional stereo panning process used to place the sound of a singer in between two loudspeakers, for example.
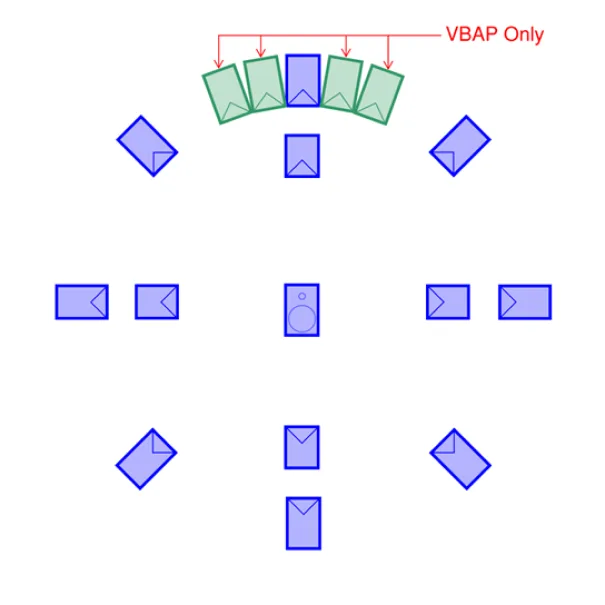
In our 3DL Studio, a 9-loudspeaker array is typically used to create a dome around the listening area. When representing a performance or presentation space, we often include a supplementary 5-loudspeaker array at the front of the studio to represent the performers or presenters more precisely, bringing the total number of loudspeakers to 14. (We are always thinking of the next addition of loudspeakers: never enough!)
During the initial planning phase, we develop a mockup sketch and storyboard for the user interface, outlining the images and controls. Now, in Max, we create a user interface with clearly marked controls (buttons, selectors, toggles) for participants to navigate listening options and track active choices visually. As listening options change, corresponding images, such as floor plans, renderings, or 3D model perspectives, guide participants in recognizing their location and the space’s conditions. A visually appealing and easily understood interface ensures access to all listening options, influencing seamless programming of signal processing for group changes and dynamic visibility based on location and selections.
06: Gather and Listen
The culmination of our work ends in two key 3DL listening sessions.
The first involves our design team, allowing us to confirm the accuracy of our current design modeling and gather impressions. This session leads to minor adjustments in the user interface, images, selection logic, and sound source balance. Occasionally, options are eliminated based on their relevance to the decisions being made.

The second session, attended by project owners and design team members is the final step that focuses on guiding critical design and budget decisions. These listeners, intimately familiar with the goals of the space, can quickly assess key listening items that will guide their design and budget decisions. The session provides a satisfying experience of finally hearing a space that’s become real—leaving participants inspired and ready to advance the design and construction process with confidence in their new insights.